
Go-数据类型
1 基本类型 类型 长度(字节) bool 1 byte 1 rune 4 int, uint 4 or 8 int8, uint8 1 int16, uint16 2 int32, uint32 4 int64, uint64 8 float32 4 float64 8 complex64 8 complex128 16 uintptr 4 or 8 类型 说明 array 值类型 struct 值类型 类型 说明 string UTF-8 字符串 类型 说明 slice 切片,引用类型 map 映射,引用类型 channel 通道,引用类型 interface 接口,引用类型 function 函数,引用类型 值类型:在赋值时复制数据,修改副本不会影响原始数据。 引用类型:在赋值时复制地址,修改数据会影响原始数据。 这里主要介绍数组,切片,映射,结构体。 2 数组 Array123var arr...
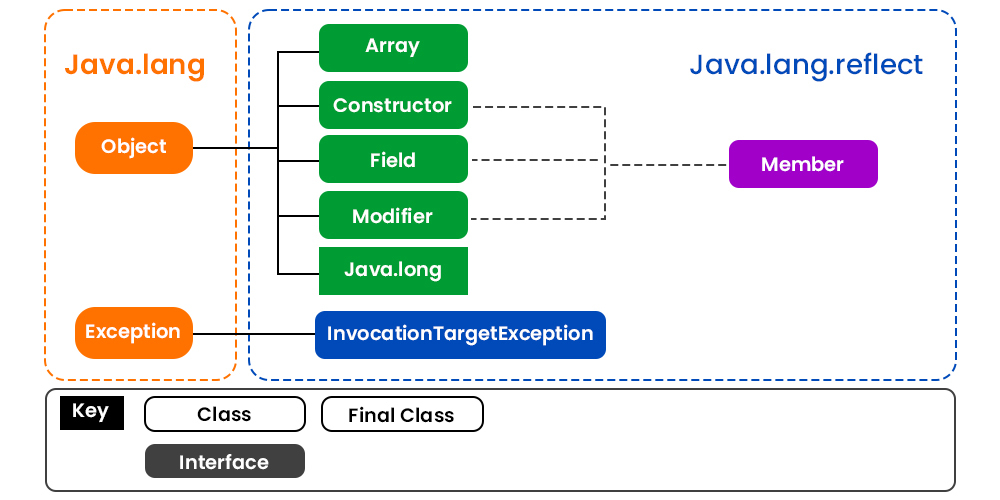
Java基础-反射
1 Class$\text {java.lang.Class}$ 反射的基础,是类的类型标识。 构造器是私有的,Class 对象只能由 JVM 创建: 123private Class(ClassLoader loader) { classLoader = loader;} 提供了获取类相关信息的核心方法: 1234567891011121314// 获取类名public String getName()// 获取修饰符public native int getModifiers()// 获取父类public native Class<? super T> getSuperclass()// 获取接口public Class<?>[] getInterfaces()// 获取构造器public Constructor<?>[] getDeclaredConstructors()// 获取方法public Method[] getDeclaredMethods()// 获取字段public Field[]...
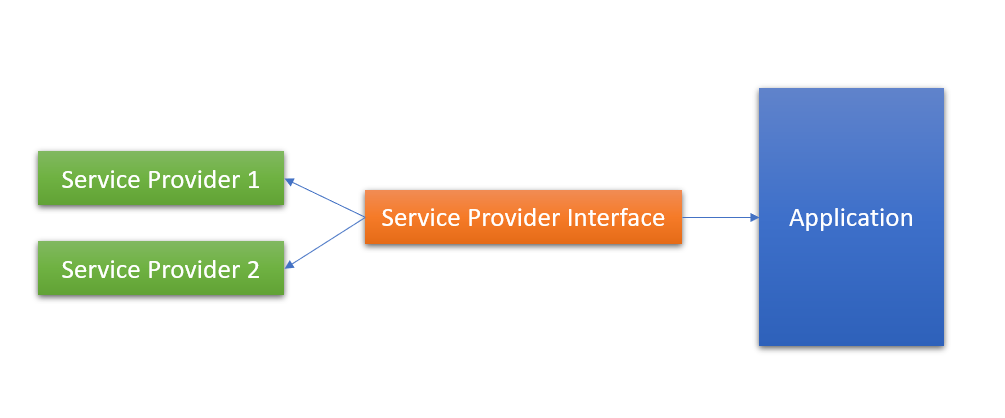
Java基础-SPI
1 简单示例 接口定义 123public interface DataBaseDriver { void connect();} 具体实现类 123456789101112131415// MySQL Implementpublic class MySQLDriver implements DataBaseDriver { @Override public void connect() { System.out.println("MySQL connecting..."); }}// PostgreSQL Implementpublic class PostgreSQLDriver implements DataBaseDriver { @Override public void connect() { System.out.println("PostgreSQL...
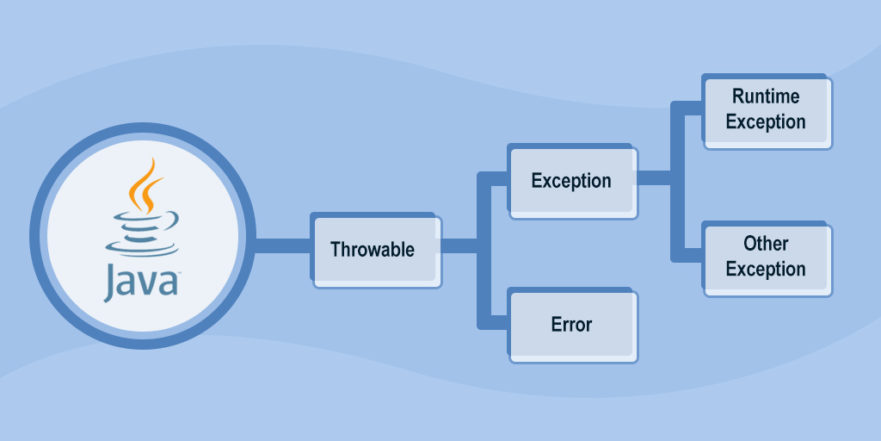
Java基础-异常
顶层基类($\text {Throwable}$),包含两个直接子类: 错误($\text {Error}$):程序无法处理的严重问题,应用程序一般无需捕获。 异常($\text {Exception}$):程序可以处理的异常,分为运行时异常和非运行时异常。 检查异常($\text {Checked Exceptions}$):编译器要求必须处置的异常。 除了 RuntimeException 及其子类以外,其他的 Exception 类及其子类。 非检查异常($\text {Unchecked Exceptions}$):编译器不要求强制处置的异常。 RuntimeException 及其子类。 Error 非检查异常可以不处理,但运行时可能会抛出。检查异常必须捕获或抛出,否则会导致编译错误。 捕获检查异常 12345try { // 可能抛出检查异常的代码} catch (IOException e) { // 处理异常} 抛出检查异常 123public void readFile()...

Java基础-泛型
1 泛型类1class className<T1, T2, ..., Tn> { /* ... */ } className:原型 <T1, T2, ..., Tn>:类型参数 单类型参数的泛型类: 1234567891011public class Box<T> { private T value; public void setValue(T value) { this.value = value; } public T getValue() { return value; }} 123456789Box<Integer> intBox = new Box<>();intBox.setValue(10);System.out.printf("intBox: %d\n", intBox.getValue());Box<String> strBox...

Java基础-注解
注解(Annotation)是 Java 5引入的一种代码元数据形式,用于为程序提供信息,可以在编译、类加载、运行时被读取,并进行相应处理。 生成文档:通过代码里标识的元数据生成 javadoc 文档。 编译检查:通过代码里标识的元数据让编译器在编译期间进行检查验证。 编译时动态处理:编译时通过代码里标识的元数据动态处理。 运行时动态处理:运行时通过代码里标识的元数据动态处理。 1 Java 内置注解Java 1.5 开始自带的标准注解,包括 @Override、@Deprecated 和 @SuppressWarnings: 1.1 @Override@Override:$\text {java.lang.Override}$ @Target(ElementType.METHOD):仅能用于方法。 @Retention(RetentionPolicy.SOURCE):仅在源代码级别有效,编译后不会保留在字节码中。 1234@Target(ElementType.METHOD)@Retention(RetentionPolicy.SOURCE)public...

![seata[feature]:support ipv6](/img/seata/seata%5Bfeature%5D-support-ipv6/cover.png)