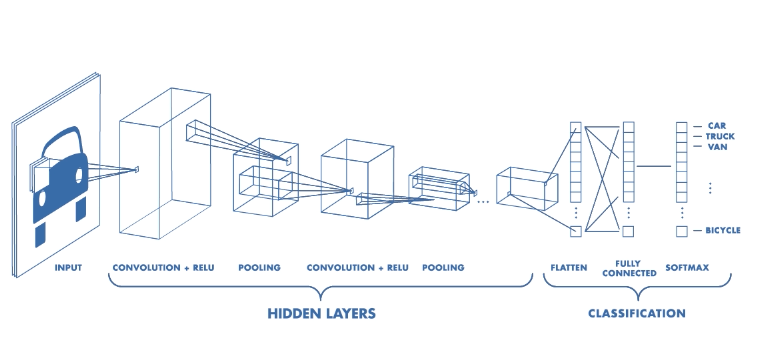
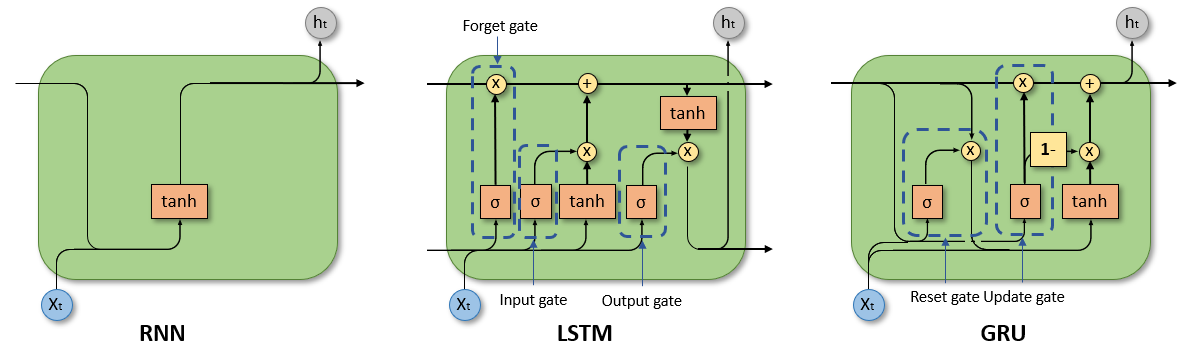
优化问题:
- 神经网络模型是非凸函数,且存在梯度消失原因
- 深度神经网络模型参数较多
泛化问题(正则化):训练数据集产生过拟合,需要通过正则化来改进泛化能力。
网络优化
网络优化目标:期望风险,最小化取自数据生成分布数据的预测误差期望。
J(θ)=E(x,y):pdata [L(f(x;θ),y)]
又通常 pdata 未知,故近似用训练集中的样本替代:pdata ≈p^data
得到经验风险,并使其最小化:
E(x,y):p^data [L(f(x;θ),y)]=N1i=1∑NL(f(x(i);θ),y(i))
- 网络结构多样性:超参数较多
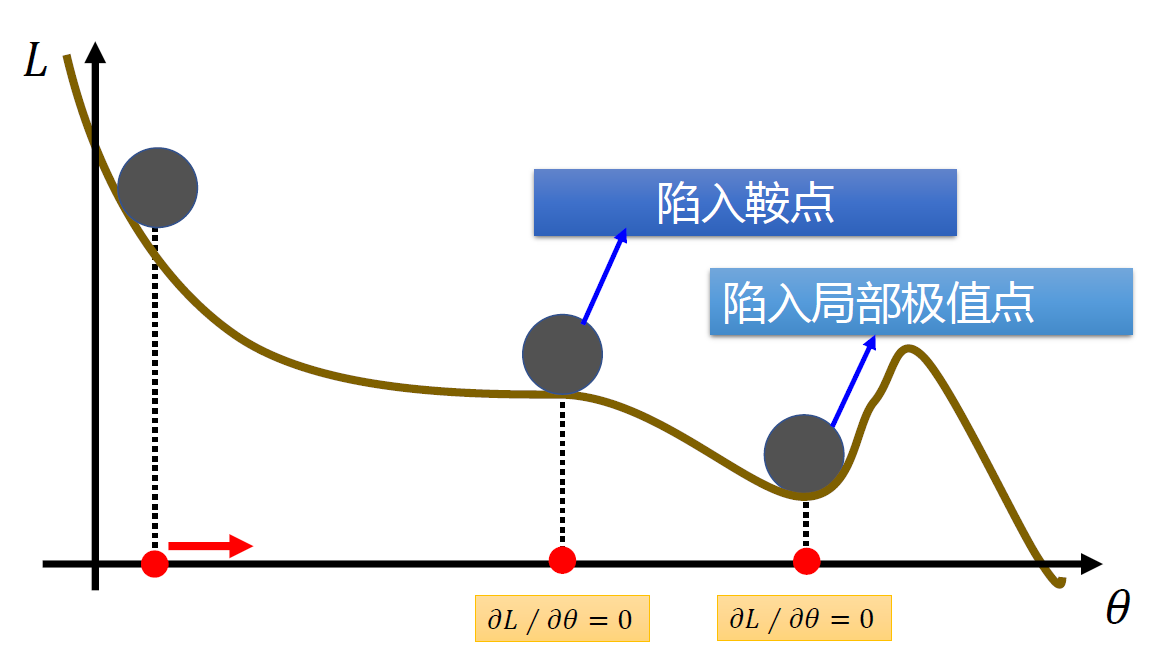
- 非凸优化问题:初始化参数、陷入局部最优点
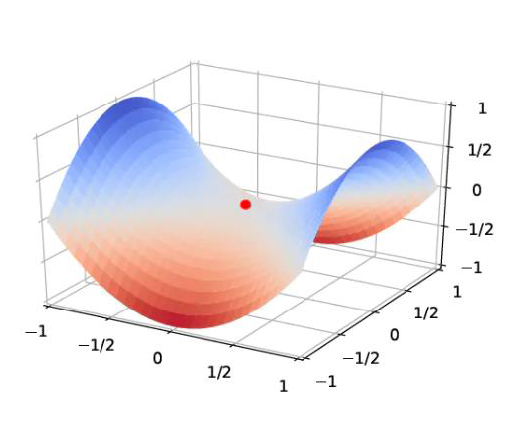
非凸优化问题在高维空间中,非凸优化最大的难点不在于如何逃离局部最优点,而是如何逃离鞍点。
一阶导数:∇L(θ)=0
二阶导数:∇2L(θ)
- ∇2L(θ)=0,驻点
- ∇2L(θ) 所有特征值为正,为局部最小点
- ∇2L(θ) 所有特征值为负,为局部最大点
- ∇2L(θ) 所有特征值有正有负,为鞍点
在高维空间中,局部最小值(Local Minima)要求在每一维度上都是最低点,这种概率非常低。也就说是,高维空间中大部分驻点都是鞍点。
==网络结构多样性==:
==非凸优化问题==:
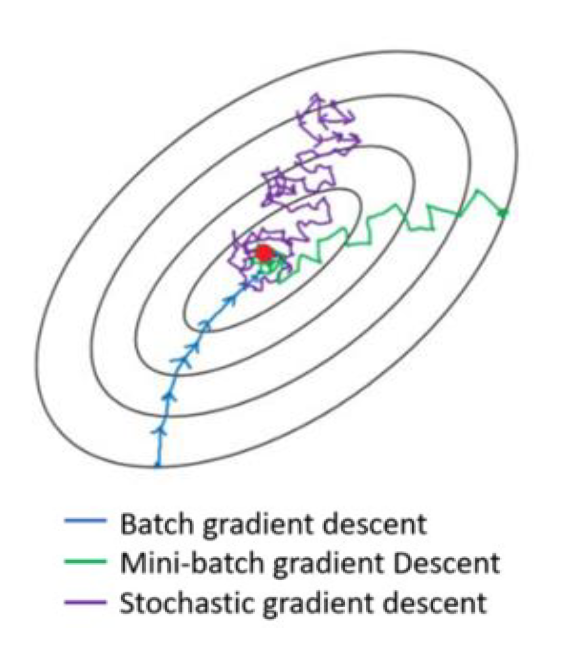
批量
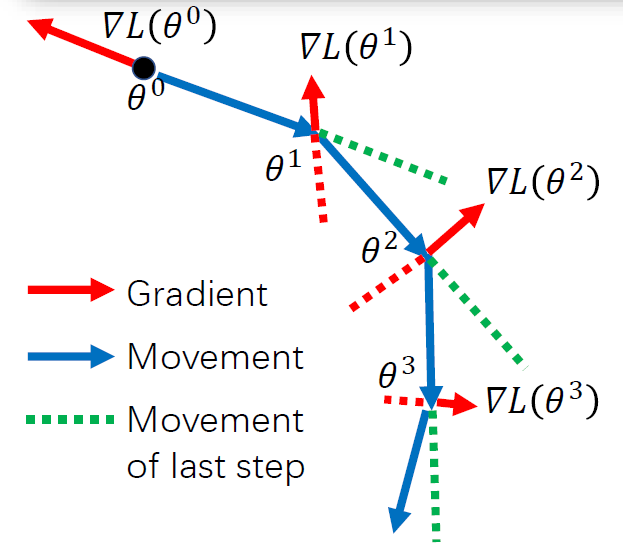
批量梯度下降
批量梯度下降(Batch Gradient Descent):每次更新都使用整个训练集数据,需要较多计算资源。
-
θ0
-
计算 θ0 梯度 ∇L(θ0),更新 θ1=θ0−α∇L(θ0)
-
计算 θ1 梯度 ∇L(θ1),更新 θ2=θ1−α∇L(θ1)
-
⋯
-
停止迭代直到 ∇L(θt)=0
∇L(θ)=N1n=1∑N∇L(f(x(n);θ),y(n))
随机梯度下降
随机梯度下降(Stochastic Gradient Descent):每次只取一个样本(编号为n)计算梯度。
∇L(θ)=∇L(f(x(n);θ),y(n))
小批量梯度下降
小批量梯度下降(Mini-batch Gradient Descent):
- 选取包含 k 个样本的小批量样本集 St:处理同批量梯度下降
- gt=∇L(θt−1)
- θt=θt−1−αgt
- θ0
- 计算 θ0 梯度 ∇L(θ0),更新 θ1=θ0−α∇L(θ0)
- 计算 θ1 梯度 ∇L(θ1),更新 θ2=θ1−α∇L(θ1)
- ⋯
- 计算 θt−1 梯度 ∇L(θt−1),更新 θt=θt−1−α∇L(θt−1)
∇L(θ)=K1(x,y)∈St∑∇L(f(x;θ),y)
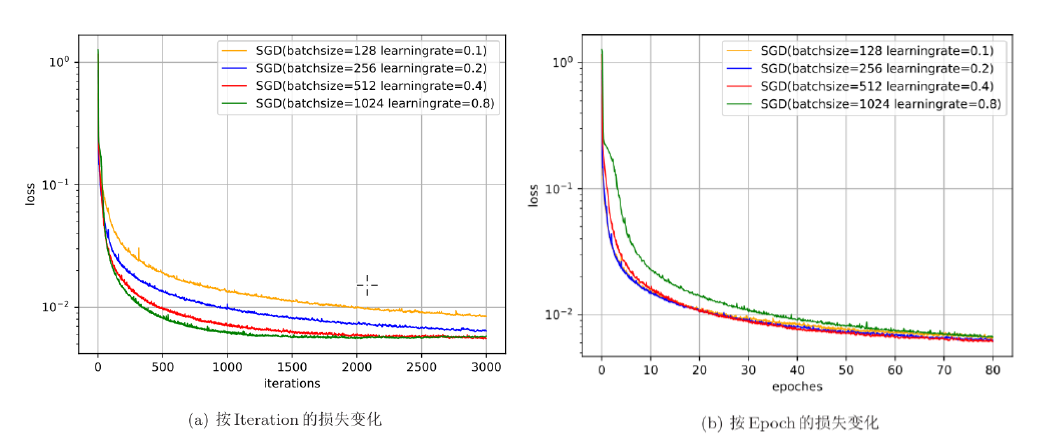
一般而言,批量(Batch Size)大小不影响梯度的期望,但是会影响梯度的方差。
- Epoch:训练样本训练次数
- Iteration:单个 Epoch 包含多次迭代
Iteration=批量大小 K训练样本的数量 N
批量越大,可以设置较大的学习率;批量越小,可以设置较小的学习率。
学习率与梯度
学习率
θt=θt−1−αgt
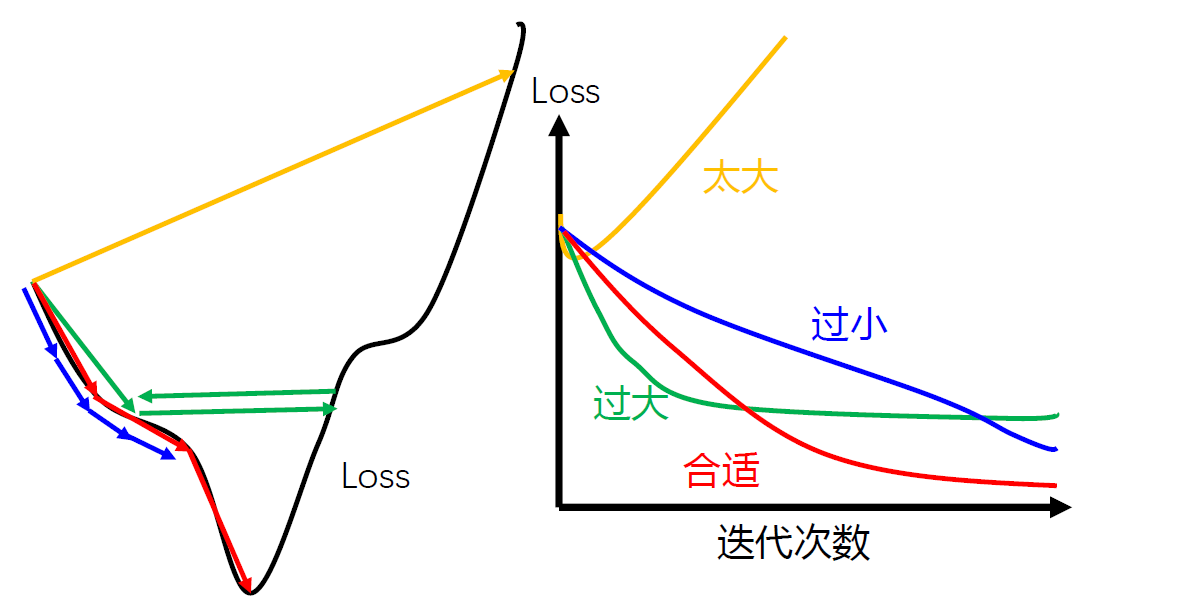
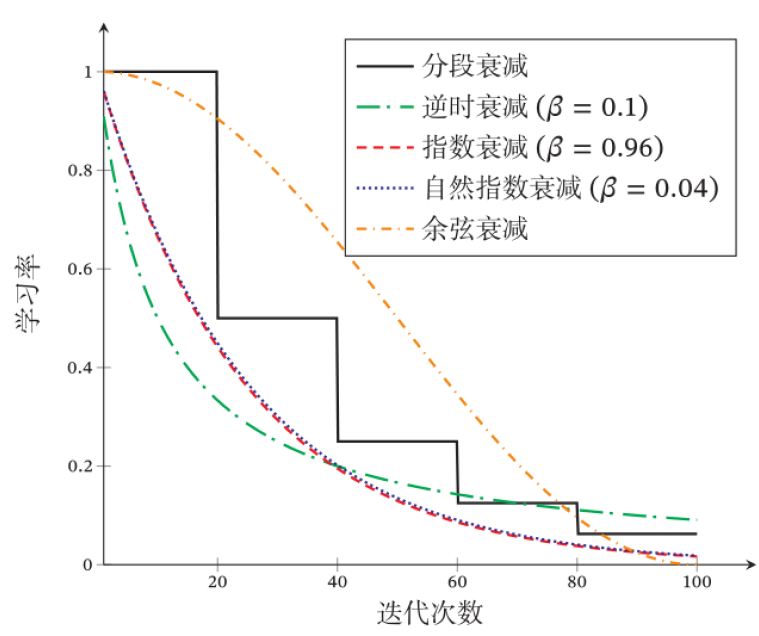
学习率衰减
==开始时,距离极值点远,保持更大保证收敛速度。迭代多次,接近极值点处,保持较小避免来回震荡。==
学习率衰减(Learning Rate Decay):
多种学习率衰减方式:β>0,设共经过 T 次迭代,当第 t 次迭代时
- 分段常数衰减:αt=α0β
- 逆时衰减: αt=α01+β×t1
- 指数衰减:αt=α0βtβ<1
- 自然指数衰减:αt=α0e−βt
- 余弦衰减:αt=21α0(1+cos(Ttπ))
学习率预热
==当 batch size 较大,需要较大的学习率,由于参数是随机初始化的,梯度往往较大,较大的学习率会使训练不稳定。==
学习率预热(Learning Rate Warmup):为提高训练稳定性,可以在最初几轮迭代时采用较小的学习率,等梯度下降到一定程度后再恢复到初始学习率。
- 逐渐预热(Gradual Warmup):设预热阶段共经过 T′ 次迭代,当第 t′ 次迭代时迭代次数为
αt=T′t′α0,1≤t′≤T′
预热结束后,再选择一种学习率衰减方法来逐渐降低学习率。
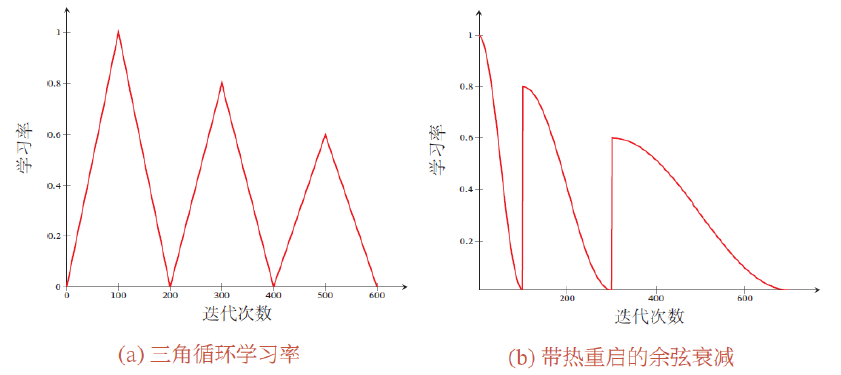
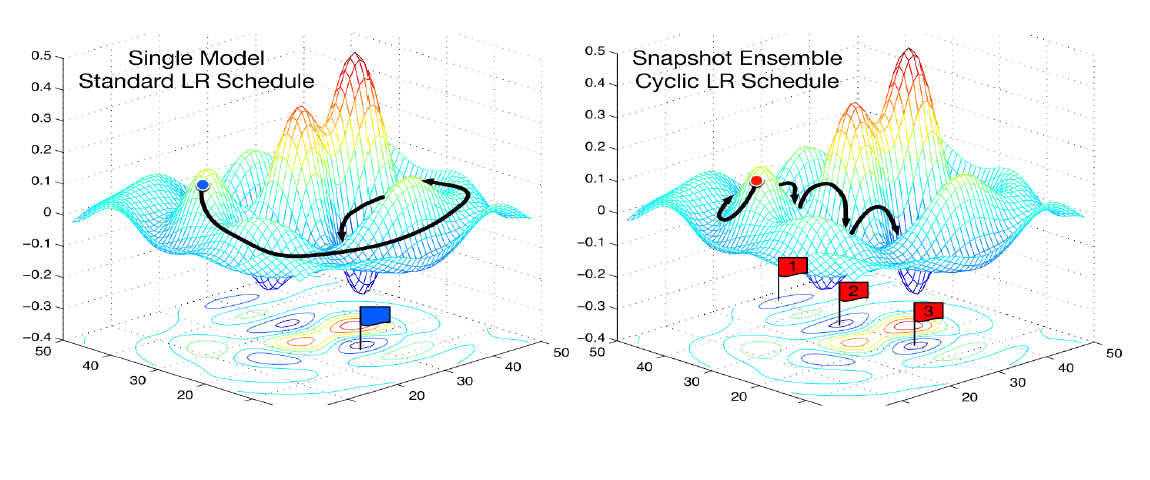
周期性学习率
==为了逃离局部最小值或鞍点,可在训练过程中周期性地增大学习率。短期内有损收敛稳定性,长期来看有助于找到更好的局部最优解。==
循环学习率(Cyclic Learning Rate):让学习率在一个区间内周期性地增大和缩小。
- 三角循环学习率(Triangular Cyclic Learning Rate):使用线性缩放来调整学习率。
- 带热重启的随机梯度下降(Stochastic Gradient Descent with Warm Restarts):周期性地重启并采用余弦衰减。
自适应学习率
学习率衰减的局限性:
- 非自适应,不能够根据当前梯度情况做出调整
- 每个参数的维度上收敛速度都不相同,应该根据不同参数的收敛情况分别设置学习率
AdaGrad 算法
- 第 t 次迭代,计算每个参数梯度平方的累计值: Gt=∑τ=1tgτ⊙gτ
- 参数更新差值: Δθt=−Gt+ϵα⊙gt
举例:wi 是模型的一个参数
θ={W1,…,Wi,…,W∣θ∣}
wi1←wi0−σi0αgi0wi2←wi1−σi1αgi1wi3←wi2−σi2αgi2⋮wit+1←wit−σitαgitσi0=(gi0)2+ϵσi1=(gi0)2+(gi1)2+ϵσi2=(gi0)2+(gi1)2+(gi2)2+ϵσit=∑τ=0t(giτ)2+ϵ
RMSprop 算法
- 第 t 次迭代,计算每个参数梯度平方的指数衰减移动平均值: Gt=βGt−1+(1−β)gt⊙gt=(1−β)∑τ=1βt−τgτ⊙gτ
- 参数更新差值: Δθt=−Gt+ϵα⊙gt
举例:wi 是模型的一个参数
θ={W1,…,Wi,…,W∣θ∣}
⋮wi1←wi0−σi0agi0σi0=β(σi0)2+ϵwi2←wi1−σi1agi1σi1=β(σi0)2+(1−β)(gi1)2+ϵwi3←wi2−σi2agi2σi2=β(σi1)2+(1−β)(gi2)2+ϵwit+1←wit−σitagitσit=β(σit−1)2+(1−β)(git)2+ϵ
梯度优化
需要进行梯度的修正缓解梯度的随机性:
Momentum 算法
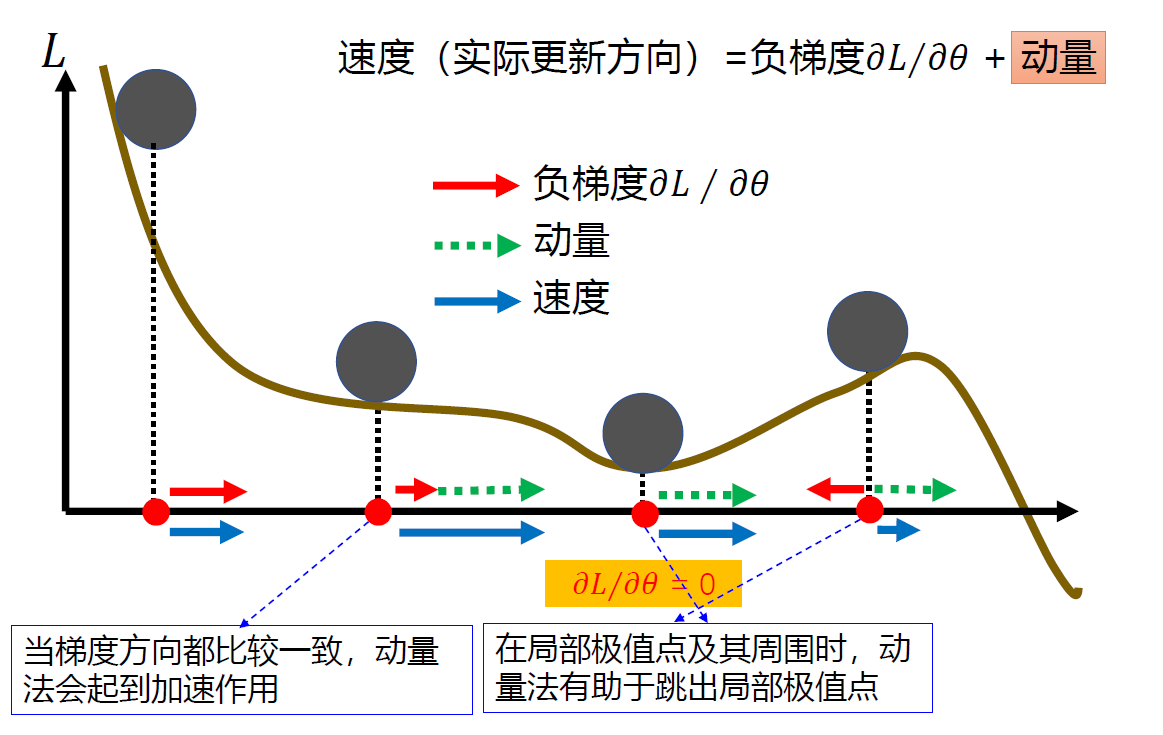
动量法(Momentum):模拟物理中的概念。一个物体的动量指的是该物体在它运动方向上保持运动的趋势,是该物体的质量和速度的乘积。用之前积累动量来替代真正的梯度,每次迭代的梯度看作是加速度。
vt=λvt−1−αgtθt+1←θt+vt
具体过程:
v0=0v1=−αg0v2=−λαg0−αg1v3=−λ2αg0−λαg1−αg2
每个参数的实际更新差值取决于最近一段时间内梯度的加权平均值。
- θ0
- 计算梯度:∇L(θ0)
- 计算速度更新:v0=0
- 计算速度更新:v1=λv0−α∇L(θ0)=−α∇L(θ0)
- θ1=θ0+v1
- 计算梯度:∇L(θ1)
- 计算速度更新:v2=λv1−α∇L(θ1)=−λα∇L(θ0)−α∇L(θ1)
- θ2=θ1+v2
- 计算梯度:∇L(θ2)
- 计算速度更新:v3=λv2−α∇L(θ2)=−λ2α∇L(θ0)−λα∇L(θ1)−α∇L(θ2)
- ⋯
当前时刻的速度不仅依赖于负梯度,还依赖于前序时刻的加权移动平均。
一般而言,在迭代初期,梯度方向都比较一致,动量法会起到加速作用,可以更快地到达最优点。在迭代后期,梯度方向会不一致,在收敛值附近震荡,动量法会起到减速作用,增加稳定性。
Adam 算法
Adam 算法:自适应学习率(RMSprop)+梯度优化算法(动量法)。
- 更新有偏一阶矩估计(梯度的指数加权平均):类似与 Momentum
vt=λvt−1−αgt−1
- 更新有偏二阶矩估计(梯度平方的指数加权平均):类似与 RMSprop
Gt=βGt−1−(1−β)gt⊙gt
- 修正一阶矩的偏差:
v^t=1−γ1tvt
- 修正二阶矩的偏差:
G^t=1−β2tGt
- 更新参数:
θt=θt−1−G^t+δαv^t
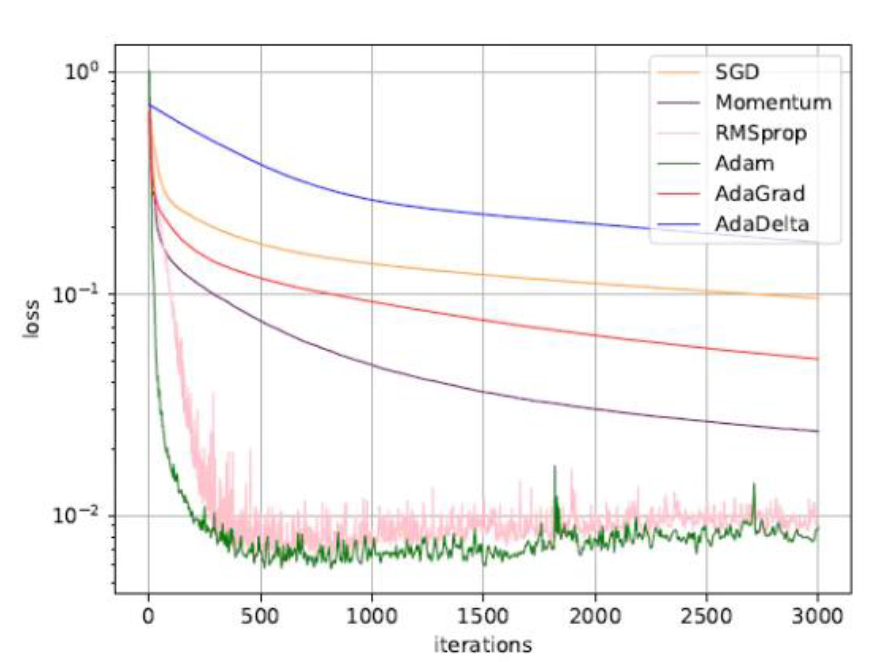
各种优化算法比较(数据集上收敛性的比较(学习率为 0.001 ,批量大小为 128)
梯度截断
除了梯度消失之外,梯度爆炸也是影响学习效率的主要因素。为了避免这种情况,当梯度的模大于一定阈值时,就对梯度进行截断,称为梯度截断(Gradient Clipping)。
gt=max(min(gt,b),a)
- 按模阶段:如果 ∥gt∥2≤b,保持 gt 不变. 如果 ∥gt∥2>b,令
gt=∥gt∥bgt
学习率与梯度优化小结
解决问题:帮助网络快速平稳收敛——逃离局部极值点、鞍点、抑制梯度爆炸。
- 学习率调整
- 学习率衰减
- 学习率预热
- 自适应算法:AdaGrad 算法/RMSprop 算法/Adam 算法
- 周期性学习率
- 梯度修正
参数初始化与数据预处理
参数初始化
基于固定方差的参数初始化
高斯分布初始化:从一个固定均值和方差的高斯分布进行随机初始化。
均匀分布初始化:在一个区间 [−r.r] 内采用均匀分布进行初始化。
一般而言,参数初始化的区间应该根据神经元的性质进行差异化的设置:一个神经元的输入连接很多,它的每个输入连接上的权重应该小一点避免神经元的输出过大(eg.ReLU)或过饱和(eg.sigmoid)。
初始化一个深度网络时,为了缓解梯度消失或者爆照问题,须尽可能保持每个神经元的输入和输出的期望始终为 0,方差保持一致:根据神经元的连接数量自适应地调整初始化分布的方差。
方差缩放的目标:
E[a[l−1]]=E[a[l]]=0Var[a[l−1]]=Var[a[l]]
基于方差缩放的参数初始化:Xavier 初始化
假设一个神经网络中,第 l 层的一个神经元输出为 a(l),与前一层 Ml−1 个神经元相连:
a(l)=f(i=1∑Ml−1wi(l)ai(l−1))
简化问题,激活函数为恒等函数 f(x)=x
假设,前一层的输出 ai(l−1) 和本层的参数 wi(l) 的均值都为 0 ,且互相独立,则 a(l) 的均值和方差分别为:
E[a(l)]=E[i=1∑Ml−1wi(l)ai(l−1)]=i=1∑Ml−1E[wi(l)]E[ai(l−1)]=0.
var(a(l))=var(i=1∑Ml−1wi(l)ai(l−1))=i=1∑Ml−1var(wi(l))var(ai(l−1))=Ml−1var(wi(l))var(ai(l−1)).
也就是要有 Ml−1var(wi(l))=1,即
var(wi(l))=Ml−11
又
var(wi(l))=Ml1
故
var(wi(l))=Ml−1+Ml2
计算出参数的理想方差后,可以通过高斯分布或者均匀分布来随机初始化参数:
- 高斯分布:N(0,Ml−1+Ml2)
- 均匀分布:r=Ml−1+Ml6
虽然在 Xavier 初始化中我们假设激活函数为恒等函数,但是 Xavier 初始化也适用于 Logistic 函数和 Tanh 函数 (神经元参数和输入都比较小,处于激活函数的线性区间)。
Logistic 函数斜率约为 41,因此 f(x)=41x
var(wi(l))=16×Ml−1+Ml2
He 初始化
当第 l 层神经元使用 ReLU 激活函数时,通常有一半的神经元输出为 0 ,因此其分布的方差也近似为使用恒等函数时的一半。这样,只考虑前向传播时,参数 wi(l) 的理想方差为:
var(wi(l))=Ml−12
计算出参数的理想方差后,可以通过高斯分布或者均匀分布来随机初始化参数:
- 高斯分布:N(0,Ml−12)
- 均匀分布:r=Ml−16
| 初始化方法 |
激活函数 |
均匀分布 |
高斯分布 |
| Xavier 初始化 |
Logistic |
r=4Ml−1+Ml6 |
σ2=16×Ml−1+Ml2 |
| Xavier 初始化 |
Tanh |
r=Ml−1+Ml6 |
σ2=Ml−1+Ml2 |
| He 初始化 |
ReLU |
r=Ml−16 |
σ2=Ml−12 |
正交初始化
用均值为 0 、方差为 1 的高斯分布初始化一个矩阵,将这个矩阵用奇异值分解得到两个正交矩阵,并使用其中之一作为权重矩阵。
数据预处理
数据归一化
- 简单缩放:最小最大值归一化;图像像素值除以 255
xi←max(xi)−min(xi)xi−min(xi)
xi←σixi−ui
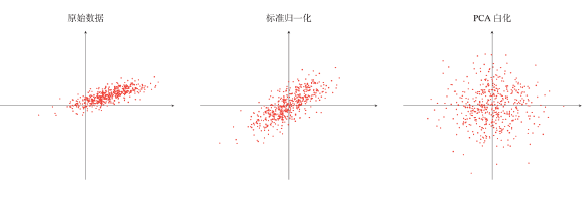
白化
降低输入的冗余性,降低特征之间的相关性,使得所有的特征具有相同的方差。
- PCA 白化:先 PCA 进行基转换,降低数据的相关性,再对每个输入特征进行缩放(除以各自的特征值的开方),以获得单位方差,此时的协方差矩阵为单位矩阵。
- ZCA 白化:ZCA 白化只是在 PCA 白化的基础上做了一个逆映射操作,使数据转换到原始基下,使得白化之后的数据更加的接近原始数据。
实际建议
| 样例 |
归一化 |
白化 |
| 自然灰度图像 |
均值消减 |
PCA/ZCA 白化 |
| 彩色图像 |
简单缩放 |
PCA/ZCA 白化 |
| 音频(MFCC/频谱图) |
特征均值化 |
PCA/ZCA 白化 |
| MNIST 手写数字 |
简单缩放/均值消减 |
PCA/ZCA 白化 |
输入数据归一化了,中间输出数据如何?
逐层归一化
目的:解决内部协变量偏移问题;解决梯度消失、梯度爆炸;获得更平滑的优化地形。
归一化方法:
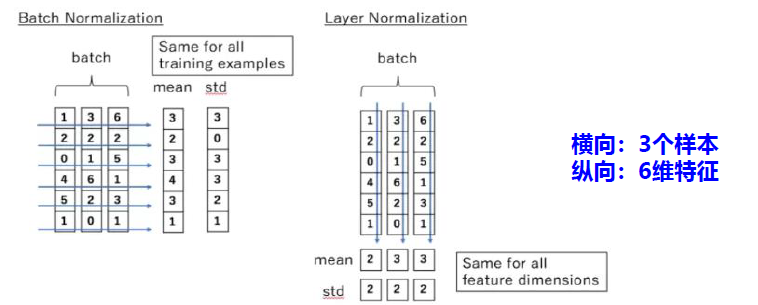
批量归一化
批量归一化是对一个中间层的单个神经元进行归一化操作。
第 l 层,对于 K 个样本的一个小批量集合 Z(l)=[z(1,l),…,z(K,l)],其均值方差为:
uB=K1k=1∑Kz(k,l)σB2=K1k=1∑K(z(k,l)−uB)⊙(z(k,l)−uB)
Z^(l)=σB2+εZ(l)−uBρˉ+β≜BNγ,β(Z(l))
针对 K 个样本进行归一化
层归一化
层归一化是对一个中间层的所有神经元进行归一化。
第 l 层,对于所有的样本集合 Z(k)=[z(k,1),…,z(k,L)]T ,其均值方差为:
uL=L1l=1∑Lz(k,l)σB2=L1l=1∑L(z(k,l)−uL)⊙(z(k,l)−uL)
Z^(l)=σ(l)2+εZ(l)−u(l)⊙γ+β≜LNγ,β(Z(l))
针对 n 个神经元进行归一化
批量归一化 VS 层归一化
批量归一化:对每一行进行归一化,不同样本同一特征。
层归一化:对每一列进行归一化,不同特征同一样本。
一般选择批量归一化,当样本数量较小时,选择层归一化。
超参数优化
神经网络中的超参数:
- 层数
- 每层神经元个数
- 激活函数
- 学习率(各优化算法中包含的参数)
- 正则化系数
- mini-batch 大小
网格搜索
网格搜索:通过尝试所有超参数的组合来寻址合适的一组超参数配置的方法。
假设一共有 K,第 k 个超参数可以取 mk 个值,一共有
m1×m2×⋯×mK
个取值组合。
随机搜索
随机搜索:对超参数进行随机组合,选取一个性能最好的配置。
贝叶斯优化
贝叶斯优化:自适应的超参数优化方法,根据当前已经试验的超参数组合,来预测下一个可能带来最大收益的组合。
假设超参数的优化函数 f(x) 服从高斯分布,则 p(f(x)∣x) 为一个正态分布
贝叶斯优化根据已有的 N 组试验结果 H={xn,yn}n=1N(yn 为 f(xn) 的观测值)来建模高斯过程,并计算 f(x) 的后验分布 pGP(f(x)∣x,H)。
需用尽可能少的样本使得后验分布接近真实分布,定义一个收益函数 a(x,H) 收益函数来判断一个样本是否能够给建模后验概率提供更多的收益,收益函数的定义有很多种方式,一个常用的是期望改善。
动态资源分配
过拟合与正则化
如何提高神经网络的泛化能力?
- ℓ1 和 ℓ2 正则化
- 提前停止
- Dropout
- 数据增强
ℓ1 和 ℓ2 正则化
ℓ1 和 ℓ2 正则化:最常用的正则化方法,通过约束参数的 ℓ1 和 ℓ2 范数来减小模型在训练数据集上的过拟合现象。
L∘′(θ)=L(θ)+λℓp(θ)
ℓ1 正则化:L′(θ)=L(θ)+λ21∥θ∥2∂θ∂L′=∂θ∂L+λθ
θt+1→θt−α∂θ∂L′=θt−α(∂θ∂L+λθt)=(1−αλ)θt−α∂θ∂L
ℓ2 正则化:L′(θ)=L(θ)+λ21∥θ∥1∂θ∂L′=∂θ∂L+λsgn(θ)
θt+1→θt−α∂θ∂L′=θt−α(∂θ∂L+λsgn(θt))=θt−α∂θ∂L−αλsgn(θt)
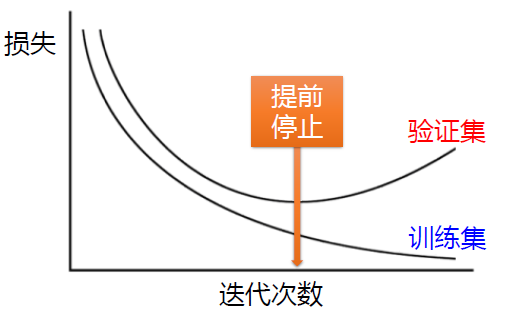
提前停止
使用一个验证集来测试每一次迭代的参数在验证集上是否最优。如果在验证集上的错误率不再下降,就停止迭代。
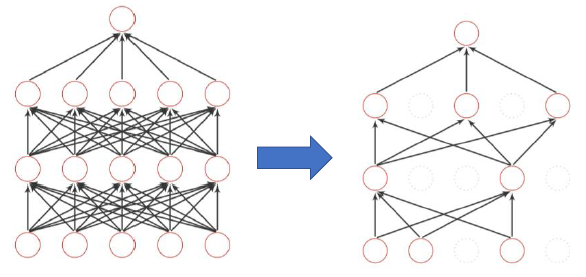
Dropout
训练:在每次更新参数前:每个神经元以 p% 的概率被丟弃(网络结构发生了改变)
测试:不用 dropout,每个参数乘以 1−p%
数据增强