动态规划
动态规划的关键在于解决重叠子问题的重复计算 ,以空间换时间的策略解决指数级复杂度的分治算法,改为多项式级的时间复杂度。
动态规划算法并非适用与所有的最优化问题,适用与动态规划求解的问题应该具备两个基本要素:最优子结构性质 和子问题重叠性质 。
最优子结构性质:问题的最优解包含其他子问题的最优解,问题的最优解分解(两个部分或多个部分、删除第一个或最后一个分量),得到的子问题的解 → \rightarrow →
子问题重叠性质:每次产生的子问题并不总是新问题,有些子问题重复出现。第 1 1 1 n n n
求解步骤
分析最优子结构性质:分析和描述该子解对应的子问题,证明该子解是对应子问题的最优解,该问题满足最优子结构性质;
基于划分的方法:问题的最优解依据问题性质划分为两个或多个子解
基于减一的方法:问题的最优解依据问题性质缩减规模
确定状态表示和状态递推方程,递归定义最优值;
确定状态转移顺序,以自底向上的方式计算出最优值;
根据计算最优值时得到的信息,构造最优解。
三类典型问题的动态规划算法:
基于划分策略构造子问题最优值与原问题最优值的递推关系
基于减一策略构造子问题最优值与原问题最优值得递推关系
状态值不是直接表示待求节问题的目标值,定义中间目标,通过中间目标值计算出原问题的最优值
矩阵连乘
问题描述 :给定 n n n A 1 \boldsymbol{A}_{1} A 1 A 2 \boldsymbol{A}_{2} A 2 ⋯ \cdots ⋯ A n \boldsymbol{A}_{n} A n A i \boldsymbol{A}_{i} A i A i + 1 \boldsymbol{A}_{i+1} A i + 1 i = 1 , 2 , ⋯ , n − 1 i=1,2, \cdots, n-1 i = 1 , 2 , ⋯ , n − 1
1⃣ C = A B \boldsymbol{C}=\boldsymbol{A B} C = A B
A \boldsymbol{A} A p × r p \times r p × r B \boldsymbol{B} B r × q r \times q r × q C \boldsymbol{C} C p × q p \times q p × q
其中 ( i , j ) (i,j) ( i , j ) c i j = ∑ k = 1 r a i k b k j c_{i j}=\sum_{k=1}^{r} a_{i k} b_{k j} c i j = ∑ k = 1 r a i k b k j i = 1 , ⋯ , p , j = 1 , ⋯ , q i=1, \cdots, p, j=1, \cdots, q i = 1 , ⋯ , p , j = 1 , ⋯ , q
A B \boldsymbol{A B} A B p × r × q p \times r \times q p × r × q
2⃣ ( ( A 1 A 2 ) A 3 ) \left(\left(\boldsymbol{A}_1 \boldsymbol{A}_2\right) \boldsymbol{A}_3\right) ( ( A 1 A 2 ) A 3 ) ( A 1 ( A 2 A 3 ) ) \left(\boldsymbol{A}_1\left(\boldsymbol{A}_2 \boldsymbol{A}_3\right)\right) ( A 1 ( A 2 A 3 ) )
A 1 \boldsymbol{A}_1 A 1 p 0 × p 1 p_{0} \times p_{1} p 0 × p 1 A 2 \boldsymbol{A}_2 A 2 p 1 × p 2 p_{1} \times p_{2} p 1 × p 2 A 3 \boldsymbol{A}_3 A 3 p 2 × p 3 p_{2} \times p_{3} p 2 × p 3
次数
( ( A 1 A 2 ) A 3 ) \left(\left(\boldsymbol{A}_1 \boldsymbol{A}_2\right) \boldsymbol{A}_3\right) ( ( A 1 A 2 ) A 3 ) p 0 p 1 p 2 + p 0 p 2 p 3 p_{0} p_{1} p_{2}+p_{0} p_{2} p_{3} p 0 p 1 p 2 + p 0 p 2 p 3 ( A 1 ( A 2 A 3 ) ) \left(\boldsymbol{A}_1\left(\boldsymbol{A}_2 \boldsymbol{A}_3\right)\right) ( A 1 ( A 2 A 3 ) ) p 0 p 1 p 3 + p 1 p 2 p 3 p_{0} p_{1} p_{3}+p_{1} p_{2} p_{3} p 0 p 1 p 3 + p 1 p 2 p 3
任意给定 n n n A 1 , A 2 , ⋯ , A n \boldsymbol{A}_{1}, \boldsymbol{A}_{2}, \cdots, \boldsymbol{A}_{n} A 1 , A 2 , ⋯ , A n p 0 × p 1 , p 1 × p 2 , ⋯ , p n − 1 × p n p_{0} \times p_{1}, p_{1} \times p_{2}, \cdots, p_{n-1} \times p_{n} p 0 × p 1 , p 1 × p 2 , ⋯ , p n − 1 × p n
输入 :多组测试数据,每组数据包含两行
第一行矩阵个数 n ( n < 1000 ) n(n<1000) n ( n < 1 0 0 0 )
第二行输入 n + 1 n+1 n + 1 p 0 , p 1 , ⋯ , p n p_{0}, p_{1}, \cdots, p_{n} p 0 , p 1 , ⋯ , p n
输出 :最少的数乘次数。
问题分析
🔴 n n n ( ( A 1 ⋯ A k ) ( A k + 1 ⋯ A n ) ) ) \left(\left(\boldsymbol{A}_{1} \cdots \boldsymbol{A}_{k}\right)\left(\boldsymbol{A}_{k+1} \cdots \boldsymbol{A}_{n}\right))\right) ( ( A 1 ⋯ A k ) ( A k + 1 ⋯ A n ) ) ) ( A 1 ⋯ A k ) \left(\boldsymbol{A}_{1} \cdots \boldsymbol{A}_{k}\right) ( A 1 ⋯ A k ) A 1 ⋯ A k \boldsymbol{A}_{1} \cdots \boldsymbol{A}_{k} A 1 ⋯ A k ( A k + 1 ⋯ A n ) \left(\boldsymbol{A}_{k+1} \cdots \boldsymbol{A}_{n}\right) ( A k + 1 ⋯ A n ) A k + 1 ⋯ A n \boldsymbol{A}_{k+1} \cdots \boldsymbol{A}_{n} A k + 1 ⋯ A n
⚫ A i ⋯ A j \boldsymbol{A}_{i} \cdots \boldsymbol{A}_{j} A i ⋯ A j A [ i : j ] \boldsymbol{A}[i: j] A [ i : j ] m ( i , j ) m(i, j) m ( i , j ) 1 ⩽ i , j ⩽ n 1 \leqslant i, j \leqslant n 1 ⩽ i , j ⩽ n m ( 1 , n ) m(1,n) m ( 1 , n )
当 i = j i=j i = j m ( i , i ) = 0 , 1 ⩽ i ⩽ n m(i, i)=0,1 \leqslant i \leqslant n m ( i , i ) = 0 , 1 ⩽ i ⩽ n
当 i < j i<j i < j m ( i , j ) = m ( i , k ) + m ( k + 1 , j ) + p i − 1 p k p j m(i, j)=m(i, k)+m(k+1, j)+p_{i-1} p_{k} p_{j} m ( i , j ) = m ( i , k ) + m ( k + 1 , j ) + p i − 1 p k p j
对于情况 2 2 2
m ( i , j ) = { 0 i = j min i ⩽ k < j { m ( i , k ) + m ( k + 1 , j ) + p i − 1 p k p j } i < j m(i, j)= \begin{cases}0 & i=j \\ \min _{i \leqslant k<j}\left\{m(i, k)+m(k+1, j)+p_{i-1} p_k p_j\right\} & i<j\end{cases}
m ( i , j ) = { 0 min i ⩽ k < j { m ( i , k ) + m ( k + 1 , j ) + p i − 1 p k p j } i = j i < j
🔵
保存已解决的子问题答案;
后续待解决的问题从保存的空间中读取。
s ( i , j ) = k s(i,j)=k s ( i , j ) = k A [ i : j ] \boldsymbol{A}[i: j] A [ i : j ] A k \boldsymbol{A}_{k} A k A k + 1 \boldsymbol{A}_{k+1} A k + 1 ( A [ i : k ] ) ( A [ k + 1 : j ] ) (\boldsymbol{A}[i: k])(\boldsymbol{A}[k+1: j]) ( A [ i : k ] ) ( A [ k + 1 : j ] )
A [ 1 : n ] \boldsymbol{A}[1: n] A [ 1 : n ] s ( 1 , n ) s(1,n) s ( 1 , n ) ( ( A 1 ⋯ A s ( 1 , n ) ) ( A s ( 1 , n ) + 1 ⋯ A n ) ) \left(\left(\boldsymbol{A}_{1} \cdots \boldsymbol{A}_{s(1, n)}\right)\left(\boldsymbol{A}_{s(1, n)+1} \cdots \boldsymbol{A}_{n}\right)\right) ( ( A 1 ⋯ A s ( 1 , n ) ) ( A s ( 1 , n ) + 1 ⋯ A n ) )
A [ 1 : s ( 1 , n ) ] \boldsymbol{A}[1: s(1,n)] A [ 1 : s ( 1 , n ) ] q = s ( 1 , s ( 1 , n ) ) q=s(1,s(1,n)) q = s ( 1 , s ( 1 , n ) ) ( ( A 1 ⋯ A q ) ( A q + 1 ⋯ A s ( 1 , n ) ) ) \left(\left(\boldsymbol{A}_{1} \cdots \boldsymbol{A}_{q}\right)\left(\boldsymbol{A}_{q+1} \cdots \boldsymbol{A}_{s(1, n)}\right)\right) ( ( A 1 ⋯ A q ) ( A q + 1 ⋯ A s ( 1 , n ) ) ) A [ s ( 1 , n ) : n ] \boldsymbol{A}[s(1,n):n ] A [ s ( 1 , n ) : n ] r = s ( s ( 1 , n ) , n ) r=s(s(1,n),n) r = s ( s ( 1 , n ) , n ) ( ( A s ( 1 , n ) + 1 ⋯ A r ) ( A r + 1 ⋯ A n ) ) \left(\left(\boldsymbol{A}_{s(1,n)+1} \cdots \boldsymbol{A}_{r}\right)\left(\boldsymbol{A}_{r+1} \cdots \boldsymbol{A}_{n}\right)\right) ( ( A s ( 1 , n ) + 1 ⋯ A r ) ( A r + 1 ⋯ A n ) )
依次类推下去,最终可以确定 A [ 1 : n ] \boldsymbol{A}[1: n] A [ 1 : n ]
算法实现与分析
矩阵连乘的动态规划算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 #include <stdio.h> #include <string.h> #define MaxNum 1000 long MatrixChain (int ) int dim[MaxNum];long memoTable[MaxNum][MaxNum];int bestK[MaxNum][MaxNum];long MatrixChain (int ) long MatrixChain (int matrixNum) int i, j, len, k; for (i = 1 ; i <= matrixNum; i++) memoTable[i][i] = 0 ; for (len = 2 ; len <= matrixNum; len++) { for (i = 1 ; i <= matrixNum - len + 1 ; i++) { j = i + len - 1 ; memoTable[i][j] = 100000000 ; for (k = i; k < j; k++) { long ans = memoTable[i][k] + memoTable[k + 1 ][j] + dim[i - 1 ] * dim[k] * dim[j]; if (ans < memoTable[i][j]) { bestK[i][j] = k; memoTable[i][j] = ans; } } } } return memoTable[1 ][matrixNum]; } int main () int i, matrixNum; while (EOF != scanf ("%d" , &matrixNum)) { for (i = 0 ; i <= matrixNum; i++) scanf ("%d" , &dim[i]); printf ("%ld\n" , MatrixChain (matrixNum)); } return 0 ; }
矩阵连乘的备忘录算法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 #include <stdio.h> #include <string.h> #define MaxNum 1000 long MatrixChainMemo (int i, int j) int dim[MaxNum];long memoTable[MaxNum][MaxNum];int bestK[MaxNum][MaxNum];long MatrixChainMemo (int , int ) long MatrixChainMemo (int i, int j) if (memoTable[i][j] != -1 ) return memoTable[i][j]; if (i == j) { memoTable[i][j] = 0 ; return 0 ; } long ans, min = 100000000 ; for (int k = i; k < j; k++) { ans = MatrixChainMemo (i, k) + MatrixChainMemo (k + 1 , j) + dim[i - 1 ] * dim[k] * dim[j]; if (ans < min) { bestK[i][j] = k; min = ans; } } memoTable[i][j] = min; return min; } int main () int i, matrixNum; memset (memoTable, -1 , sizeof (memoTable)); while (EOF != scanf ("%d" , &matrixNum)) { for (i = 0 ; i <= matrixNum; i++) scanf ("%d" , &dim[i]); printf ("%ld\n" , MatrixChainMemo (1 , matrixNum)); } return 0 ; }
一般来讲,
当一个问题的所有子问题至少都要解一次时,自底向上的动态规划算法比自顶向下的备忘录算法效率高。
当一个问题的部分子问题不需要求解时,自顶向下的备忘录算法比自底向上的动态规划算法效率高。
最优二叉搜索树
问题描述 :设是有序集 S = { S 1 , S 2 , ⋯ , S n } S=\left\{S_{1}, S_{2}, \cdots, S_{n}\right\} S = { S 1 , S 2 , ⋯ , S n } s 1 < s 2 < ⋯ < s n s_{1}<s_{2}<\cdots<s_{n} s 1 < s 2 < ⋯ < s n S S S S S S
二叉搜索树 :任意结点中的元素 s s s
假设 S S S s i s_{i} s i p i ( 0 < p i < 1 ) p_{i}(0<p_{i}<1) p i ( 0 < p i < 1 ) S S S n + 1 n+1 n + 1 e 0 , e 1 , ⋯ , e n e_{0}, e_{1}, \cdots, e_{n} e 0 , e 1 , ⋯ , e n S S S q i ( 0 < q i < 1 ) q_{i}(0<q_{i}<1) q i ( 0 < q i < 1 )
e 0 e_{0} e 0 s 1 s_{1} s 1 e n e_{n} e n s n s_{n} s n 对于 i = 1 , 2 , . . . , n − 1 i=1,2,...,n-1 i = 1 , 2 , . . . , n − 1 e i e_{i} e i ( s i , s i + 1 ) (s_{i},s_{i+1}) ( s i , s i + 1 )
这样得到了结点分类:
s i s_{i} s i p i p_{i} p i e i e_{i} e i q i q_{i} q i
每次检索要么成功,查询到实结点;要么失败,查询到虚结点。
∑ i = 1 n p i + ∑ i = 0 n q i = 1 \sum_{i=1}^n p_i+\sum_{i=0}^n q_i=1
i = 1 ∑ n p i + i = 0 ∑ n q i = 1
对于一个有序集 S S S S = { S 1 , S 2 , ⋯ , S n } S=\left\{S_{1}, S_{2}, \cdots, S_{n}\right\} S = { S 1 , S 2 , ⋯ , S n } T T T
实结点 s i s_{i} s i d p ( s i ) dp(s_{i}) d p ( s i ) 0 0 0 p i p_{i} p i 1 ⩽ i ⩽ n 1 \leqslant i \leqslant n 1 ⩽ i ⩽ n
虚结点 e j e_{j} e j d p ( e j ) dp(e_{j}) d p ( e j ) q j q_{j} q j 0 ⩽ j ⩽ n 0 \leqslant j \leqslant n 0 ⩽ j ⩽ n
根据二叉树的特性
如果在深度为 d p ( s i ) dp(s_{i}) d p ( s i ) s i s_{i} s i d p ( s i ) + 1 dp(s_{i})+1 d p ( s i ) + 1
如果在深度为 d p ( e j ) dp(e_{j}) d p ( e j ) e j e_{j} e j d p ( e j ) dp(e_{j}) d p ( e j )
二叉搜索树 T T T
C = ∑ i = 1 n p i ( d p ( s i ) + 1 ) + ∑ j = 1 n q j dp ( e j ) C=\sum_{i=1}^{n} p_{i}\left(\mathrm{dp}\left(s_{i}\right)+1\right)+\sum_{j=1}^{n} q_{j} \operatorname{dp}\left(e_{j}\right)
C = i = 1 ∑ n p i ( d p ( s i ) + 1 ) + j = 1 ∑ n q j d p ( e j )
最优二叉搜索树 :在所有表示有序集 S S S
现在给定有序集 S S S p i p_{i} p i q j q_{j} q j
输入 :
多组测试数据,每组数据包含三行
有序集 S S S n ( n < 1000 ) n(n<1000) n ( n < 1 0 0 0 )
S S S n n n p p p S S S n + 1 n+1 n + 1 q q q
输出 :
最优二叉树的平均比较次数,保留四位有效数字。每组测试样例输出一行。
问题分析
🔴
T ( 1 , n ) T(1,n) T ( 1 , n ) { s 1 , s 2 , ⋯ , s n } \left\{s_{1}, s_{2}, \cdots, s_{n}\right\} { s 1 , s 2 , ⋯ , s n } { e 0 , e 1 , ⋯ , e n } \left\{e_{0}, e_{1}, \cdots, e_{n}\right\} { e 0 , e 1 , ⋯ , e n }
T ( 1 , k − 1 ) T(1,k-1) T ( 1 , k − 1 ) { s 1 , s 2 , ⋯ , s k − 1 } \left\{s_{1}, s_{2}, \cdots, s_{k-1}\right\} { s 1 , s 2 , ⋯ , s k − 1 } { e 0 , e 1 , ⋯ , e k − 1 } \left\{e_{0}, e_{1}, \cdots, e_{k-1}\right\} { e 0 , e 1 , ⋯ , e k − 1 }
T ( k + 1 , n ) T(k+1,n) T ( k + 1 , n ) { s k + 1 , s 2 , ⋯ , s n } \left\{s_{k+1}, s_{2}, \cdots, s_{n}\right\} { s k + 1 , s 2 , ⋯ , s n } { e k , e k + 1 , ⋯ , e n } \left\{e_{k}, e_{k+1}, \cdots, e_{n}\right\} { e k , e k + 1 , ⋯ , e n }
假设 T ( 1 , n ) T(1,n) T ( 1 , n ) { s 1 , s 2 , ⋯ , s n } \left\{s_{1}, s_{2}, \cdots, s_{n}\right\} { s 1 , s 2 , ⋯ , s n } { e 0 , e 1 , ⋯ , e n } \left\{e_{0}, e_{1}, \cdots, e_{n}\right\} { e 0 , e 1 , ⋯ , e n }
T ( 1 , k − 1 ) T(1,k-1) T ( 1 , k − 1 ) { s 1 , s 2 , ⋯ , s k − 1 } \left\{s_{1}, s_{2}, \cdots, s_{k-1}\right\} { s 1 , s 2 , ⋯ , s k − 1 } { e 0 , e 1 , ⋯ , e k − 1 } \left\{e_{0}, e_{1}, \cdots, e_{k-1}\right\} { e 0 , e 1 , ⋯ , e k − 1 }
T ( k + 1 , n ) T(k+1,n) T ( k + 1 , n ) { s k + 1 , s 2 , ⋯ , s n } \left\{s_{k+1}, s_{2}, \cdots, s_{n}\right\} { s k + 1 , s 2 , ⋯ , s n } { e k , e k + 1 , ⋯ , e n } \left\{e_{k}, e_{k+1}, \cdots, e_{n}\right\} { e k , e k + 1 , ⋯ , e n }
⚫
T ( i , j ) T(i,j) T ( i , j ) i i i j j j
C ( i , j ) C(i,j) C ( i , j ) T ( i , j ) T(i,j) T ( i , j )
C ( 1 , n ) C(1,n) C ( 1 , n )
j = i − 1 j=i-1 j = i − 1 C ( i , j ) = 0 C(i, j)=0 C ( i , j ) = 0 j > i − 1 j>i-1 j > i − 1 C ( i , j ) C(i,j) C ( i , j )
根结点s r s_{r} s r i ⩽ r ⩽ j i \leqslant r \leqslant j i ⩽ r ⩽ j
左子树:T ( i , r − 1 ) T(i,r-1) T ( i , r − 1 )
右子树:T ( r + 1 , j ) T(r+1,j) T ( r + 1 , j )
当一颗二叉树成为一个结点的子树时,则子树中每个结点的深度加 1 1 1
树 T ( i , r − 1 ) T(i,r-1) T ( i , r − 1 ) s r s_r s r C ′ ( i , r − 1 ) = C ( i , r − 1 ) + ∑ k = i r − 1 p k + ∑ k = i − 1 r − 1 q k C^{\prime}(i, r-1)=C(i, r-1)+\sum_{k=i}^{r-1} p_{k}+\sum_{k=i-1}^{r-1} q_{k} C ′ ( i , r − 1 ) = C ( i , r − 1 ) + ∑ k = i r − 1 p k + ∑ k = i − 1 r − 1 q k
树 T ( r + 1 , j ) T(r+1,j) T ( r + 1 , j ) s r s_r s r C ′ ( r + 1 , j ) = C ( r + 1 , j ) + ∑ k = r + 1 j p k + ∑ k = r j q k C^{\prime}(r+1, j)=C(r+1, j)+\sum_{k=r+1}^{j} p_{k}+\sum_{k=r}^{j} q_{k} C ′ ( r + 1 , j ) = C ( r + 1 , j ) + ∑ k = r + 1 j p k + ∑ k = r j q k
根结点的平均比较次数为 p r p_r p r
C ( i , j ) = C ′ ( i , r − 1 ) + C ′ ( r + 1 , j ) + p r = C ( i , r − 1 ) + ∑ k = i r − 1 p k + ∑ k = i − 1 r − 1 q k + C ( r + 1 , j ) + ∑ k = r + 1 r − j p k + ∑ k = r j q k + p r = C ( i , r − 1 ) + C ( r + 1 , j ) + ∑ k = i j p k + ∑ k = i − 1 j q k \begin{aligned}C(i, j) &=C^{\prime}(i, r-1)+C^{\prime}(r+1, j)+p_{r} \\&=C(i, r-1)+\sum_{k=i}^{r-1} p_{k}+\sum_{k=i-1}^{r-1} q_{k}+C(r+1, j)+\sum_{k=r+1}^{r-j} p_{k}+\sum_{k=r}^{j} q_{k}+p_{r} \\&=C(i, r-1)+C(r+1, j)+\sum_{k=i}^{j} p_{k}+\sum_{k=i-1}^{j} q_{k}\end{aligned}
C ( i , j ) = C ′ ( i , r − 1 ) + C ′ ( r + 1 , j ) + p r = C ( i , r − 1 ) + k = i ∑ r − 1 p k + k = i − 1 ∑ r − 1 q k + C ( r + 1 , j ) + k = r + 1 ∑ r − j p k + k = r ∑ j q k + p r = C ( i , r − 1 ) + C ( r + 1 , j ) + k = i ∑ j p k + k = i − 1 ∑ j q k
令 ω ( i , j ) = ∑ k = i j p k + ∑ k = i − 1 j q k \omega(i, j)=\sum_{k=i}^{j} p_{k}+\sum_{k=i-1}^{j} q_{k} ω ( i , j ) = ∑ k = i j p k + ∑ k = i − 1 j q k
最终表示为:
C ( i , j ) = C ( i , r − 1 ) + C ( r + 1 , j ) + ω ( i , j ) C(i, j)=C(i, r-1)+C(r+1, j)+\omega(i, j)
C ( i , j ) = C ( i , r − 1 ) + C ( r + 1 , j ) + ω ( i , j )
又最优二叉搜索树的根结点无法事先确定,我们枚举所有可能的根结点 s r s_{r} s r i ⩽ r ⩽ j i \leqslant r \leqslant j i ⩽ r ⩽ j C ( i , j ) C(i,j) C ( i , j )
C ( i , j ) = { 0 , j = i − 1 ω ( i , j ) + min i ⩽ r ⩽ j { C ( i , r − 1 ) + C ( r + 1 , j ) } , i ⩽ j C(i, j)= \begin{cases}0, & j=i-1 \\ \omega(i, j)+\min _{i \leqslant r \leqslant j}\{C(i, r-1)+C(r+1, j)\}, & i \leqslant j\end{cases}
C ( i , j ) = { 0 , ω ( i , j ) + min i ⩽ r ⩽ j { C ( i , r − 1 ) + C ( r + 1 , j ) } , j = i − 1 i ⩽ j
🔵
算法实现与分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 #include <stdio.h> #include <string.h> #define MaxNum 1000 double C[MaxNum][MaxNum], root[MaxNum][MaxNum];double w[MaxNum][MaxNum];double OptimalBST (double *p, double *q, int n) double OptimalBST (double *p, double *q, int n) int i, j, r, k; for (i = 0 ; i < n; i++) { w[i + 1 ][i] = q[i]; C[i + 1 ][i] = 0 ; } for (r = 0 ; r < n; r++) { for (i = 1 ; i <= n - r; i++) { j = i + r; w[i][j] = w[i][j - 1 ] + p[j] + q[j]; C[i][j] = C[i + 1 ][j]; root[i][j] = i; for (k = i + 1 ; k <= j; k++) { double dTemp = C[i][k - 1 ] + C[k + 1 ][j]; if (dTemp < C[i][j]) { C[i][j] = dTemp; root[i][j] = k; } } C[i][j] += w[i][j]; } } return C[1 ][n]; } int main () int n; double pProb[MaxNum], qProb[MaxNum]; while (EOF != scanf ("%d" , &n)) { for (int i = 1 ; i <= n; i++) scanf ("%lf" , &pProb[i]); for (int i = 0 ; i <= n; i++) scanf ("%lf" , &qProb[i]); printf ("%1.4lf\n" , OptimalBST (pProb, qProb, n)); } return 0 ; }
多段图最短路径
问题分析
算法设计与实现
最长公共子序列
问题描述 :若给定序列 X = { x 1 , x 2 , ⋯ , x m } X=\left\{x_{1}, x_{2}, \cdots, x_{m}\right\} X = { x 1 , x 2 , ⋯ , x m } Z = { z 1 , z 2 , ⋯ , z k } Z=\left\{z_{1}, z_{2}, \cdots, z_{k}\right\} Z = { z 1 , z 2 , ⋯ , z k } Z Z Z X X X { i 1 , i 2 , ⋯ , i k } \left\{i_{1}, i_{2}, \cdots, i_{k}\right\} { i 1 , i 2 , ⋯ , i k } j = 1 , 2 , . . . , j j=1,2,...,j j = 1 , 2 , . . . , j z j = x i j z_{j}=x_{i_{j}} z j = x i j
举例:Z = { B , C , D , B } Z=\{B, C, D, B\} Z = { B , C , D , B } X = { A , B , C , B , D , A , B } X=\{A, B, C, B, D, A, B\} X = { A , B , C , B , D , A , B } { 2 , 3 , 5 , 7 } \{2,3,5,7\} { 2 , 3 , 5 , 7 }
z 1 = x 2 = B z_{1}=x_{2}=B z 1 = x 2 = B z 2 = x 3 = C z_{2}=x_{3}=C z 2 = x 3 = C z 3 = x 5 = D z_{3}=x_{5}=D z 3 = x 5 = D z 4 = x 7 = B z_{4}=x_{7}=B z 4 = x 7 = B
{ i 1 , i 2 , ⋯ , i k } \left\{i_{1}, i_{2}, \cdots, i_{k}\right\} { i 1 , i 2 , ⋯ , i k } { 2 , 3 , 5 , 7 } \{2,3,5,7\} { 2 , 3 , 5 , 7 }
给定序列 X X X Y Y Y Z Z Z X X X Y Y Y Z Z Z X X X Y Y Y 公共子序列 。其中在这些公共子序列中,包含元素最多的序列称为最长公共子序列 。任意给定两个字符序列 X = { x 1 , x 2 , ⋯ , x m } X=\left\{x_{1}, x_{2}, \cdots, x_{m}\right\} X = { x 1 , x 2 , ⋯ , x m } Y = { y 1 , y 2 , ⋯ , y n } Y=\left\{y_{1}, y_{2}, \cdots, y_{n}\right\} Y = { y 1 , y 2 , ⋯ , y n }
输入 :
包含多组测试数据
第一行输入字符序列 X X X
第二行输入字符序列 Y Y Y
X X X Y Y Y
输出 :最长公共子序列的长度,每组测试数据输出一行。
问题分析
🔴 X = { x 1 , x 2 , ⋯ , x m } X=\left\{x_{1}, x_{2}, \cdots, x_{m}\right\} X = { x 1 , x 2 , ⋯ , x m } Y = { y 1 , y 2 , ⋯ , y n } Y=\left\{y_{1}, y_{2}, \cdots, y_{n}\right\} Y = { y 1 , y 2 , ⋯ , y n } Z = { z 1 , z 2 , ⋯ , z k } Z=\left\{z_{1}, z_{2}, \cdots, z_{k}\right\} Z = { z 1 , z 2 , ⋯ , z k }
若 x m = y n x_{m}=y_{n} x m = y n z k = x m = y n z_{k}=x_{m}=y_{n} z k = x m = y n Z k − 1 = { z 1 , z 2 , ⋯ , z k − 1 } Z_{k-1}=\left\{z_{1}, z_{2}, \cdots, z_{k-1}\right\} Z k − 1 = { z 1 , z 2 , ⋯ , z k − 1 } X m − 1 = { x 1 , x 2 , ⋯ , x m − 1 } X_{m-1}=\left\{x_{1}, x_{2}, \cdots, x_{m-1}\right\} X m − 1 = { x 1 , x 2 , ⋯ , x m − 1 } Y n − 1 = { y 1 , y 2 , ⋯ , y n − 1 } Y_{n-1}=\left\{y_{1}, y_{2}, \cdots, y_{n-1}\right\} Y n − 1 = { y 1 , y 2 , ⋯ , y n − 1 }
若 x m ≠ y n x_{m} \neq y_{n} x m = y n z k ≠ x m z_{k}\neq x_{m} z k = x m Z Z Z X m − 1 X_{m-1} X m − 1 Y Y Y
若 x m ≠ y n x_{m} \neq y_{n} x m = y n z k ≠ y n z_{k} \neq y_{n} z k = y n Z Z Z X X X Y n − 1 Y_{n-1} Y n − 1
⚫ C ( i , j ) C(i, j) C ( i , j ) X i = { x 1 , x 2 , ⋯ , x i } X_{i}=\left\{x_{1}, x_{2}, \cdots, x_{i}\right\} X i = { x 1 , x 2 , ⋯ , x i } Y j = { y 1 , y 2 , ⋯ , y j } Y_{j}=\left\{y_{1}, y_{2}, \cdots, y_{j}\right\} Y j = { y 1 , y 2 , ⋯ , y j }
当 i = 0 i=0 i = 0 j = 0 j=0 j = 0 C ( 0 , 0 ) = 0 C(0,0)=0 C ( 0 , 0 ) = 0
当 i , j > 0 i,j>0 i , j > 0
x i = y j x_{i}=y_{j} x i = y j C ( i , j ) = C ( i − 1 , j − 1 ) + 1 C(i, j)=C(i-1, j-1)+1 C ( i , j ) = C ( i − 1 , j − 1 ) + 1 x i ≠ y j x_{i} \neq y_{j} x i = y j C ( i , j ) = m a x ( C ( i − 1 , j ) , C ( i , j − 1 ) ) C(i, j)=max(C(i-1,j),C(i,j-1)) C ( i , j ) = m a x ( C ( i − 1 , j ) , C ( i , j − 1 ) )
( X i − 1 , Y j ) \left(X_{i-1}, Y_{j}\right) ( X i − 1 , Y j ) ( X i , Y j − 1 ) \left(X_{i}, Y_{j-1}\right) ( X i , Y j − 1 )
综上所述,C ( i , j ) C(i,j) C ( i , j )
C ( x , y ) = { 0 , i = 0 , j = 0 C ( i − 1 , j − 1 ) + 1 , i , j > 0 , x i = y j max { C ( i − 1 , j ) , C ( i , j − 1 ) } , i , j > 0 , x i ≠ y j C(x, y)=\left\{\begin{array}{ll}0, & i=0, j=0 \\C(i-1, j-1)+1, & i, j>0, x_{i}=y_{j} \\\max \{C(i-1, j), C(i, j-1)\}, & i, j>0, x_{i} \neq y_{j}\end{array}\right.
C ( x , y ) = ⎩ ⎪ ⎨ ⎪ ⎧ 0 , C ( i − 1 , j − 1 ) + 1 , max { C ( i − 1 , j ) , C ( i , j − 1 ) } , i = 0 , j = 0 i , j > 0 , x i = y j i , j > 0 , x i = y j
🔵
二维数组 C [ i ] [ j ] C[i][j] C [ i ] [ j ] X i = { x 1 , x 2 , ⋯ , x i } X_{i}=\left\{x_{1}, x_{2}, \cdots, x_{i}\right\} X i = { x 1 , x 2 , ⋯ , x i } Y j = { y 1 , y 2 , ⋯ , y j } Y_{j}=\left\{y_{1}, y_{2}, \cdots, y_{j}\right\} Y j = { y 1 , y 2 , ⋯ , y j }
二维数组 B [ i ] [ j ] B[i][j] B [ i ] [ j ] C [ i ] [ j ] C[i][j] C [ i ] [ j ]
B [ i ] [ j ] = 1 B[i][j]=1 B [ i ] [ j ] = 1 C [ i ] [ j ] C[i][j] C [ i ] [ j ] C [ i − 1 ] [ j − 1 ] C[i-1][j-1] C [ i − 1 ] [ j − 1 ] B [ i ] [ j ] = 2 B[i][j]=2 B [ i ] [ j ] = 2 C [ i ] [ j ] C[i][j] C [ i ] [ j ] C [ i − 1 ] [ j ] C[i-1][j] C [ i − 1 ] [ j ] B [ i ] [ j ] = 3 B[i][j]=3 B [ i ] [ j ] = 3 C [ i ] [ j ] C[i][j] C [ i ] [ j ] C [ i ] [ j − 1 ] C[i][j-1] C [ i ] [ j − 1 ]
输入序列为空的情形,C ( i , 0 ) = 0 C(i,0)=0 C ( i , 0 ) = 0 C ( 0 , j ) = 0 C(0,j)=0 C ( 0 , j ) = 0 C C C
计算
i = 1 i=1 i = 1 j = 1 , 2 , . . . , m j=1,2,...,m j = 1 , 2 , . . . , m C ( i , j ) C(i,j) C ( i , j ) i = 2 i=2 i = 2 j = 1 , 2 , . . . , m j=1,2,...,m j = 1 , 2 , . . . , m C ( i , j ) C(i,j) C ( i , j ) ⋯ \cdots ⋯ i = n i=n i = n j = 1 , 2 , . . . , m j=1,2,...,m j = 1 , 2 , . . . , m C ( i , j ) C(i,j) C ( i , j )
依次填充 C [ i ] [ j ] C[i][j] C [ i ] [ j ]
算法实现与分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 #include <stdio.h> #include <string.h> #define MAX 100 int lcsLength (char *, char *) int lcsLength (char *strX, char *strY) int C[MAX][MAX], B[MAX][MAX], i, j; int m = strlen (strX) + 1 ; int n = strlen (strY) + 1 ; for (i = 0 ; i < m; i++) C[i][0 ] = 0 ; for (j = 0 ; j < n; j++) C[0 ][j] = 0 ; for (i = 1 ; i < m; i++) { for (j = 1 ; j < n; j++) { if (strX[i - 1 ] == strY[j - 1 ]) { C[i][j] = C[i - 1 ][j - 1 ] + 1 ; B[i][j] = 1 ; } else if (C[i - 1 ][j] >= C[i][j - 1 ]) { C[i][j] = C[i - 1 ][j]; B[i][j] = 2 ; } else { C[i][j] = C[i][j - 1 ]; B[i][j] = 3 ; } } } return C[m - 1 ][n - 1 ]; } int main () char strX[MAX], strY[MAX]; while (EOF != scanf ("%s%s" , strX, strY)) { int ans = lcsLength (strX, strY); printf ("%d\n" , ans); } return 0 ; }
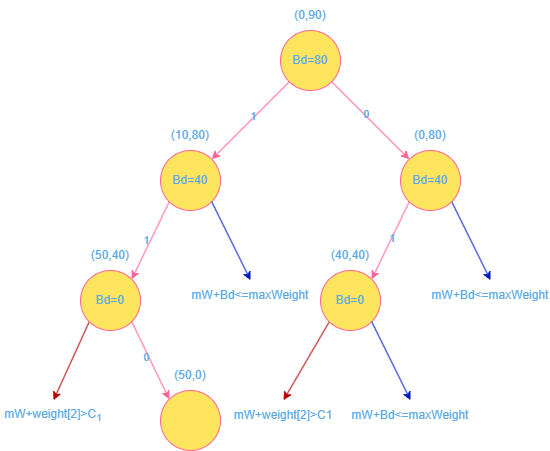
0-1 背包问题
问题分析
算法实现与分析
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #include <cstdio> #include <cstring> #define MaxN 1000 #define MaxC 1000 int n, C;int w[MaxN];double v[MaxN];double Val[MaxC];double binaryKnapsack (int , int *, double *, int ) double binaryKnapsack (int numItems, int *w, double *v, int capacity) memset (Val, 0 , sizeof (Val)); for (int i = 0 ; i < numItems; i++) for (int j = capacity; j >= 0 ; j--) if (j >= w[i] && Val[j] < Val[j - w[i]] + v[i]) Val[j] = Val[j - w[i]] + v[i]; return Val[capacity]; } int main () while (scanf ("%d%d" , &n, &C) != EOF) { for (int i = 0 ; i < n; i++) scanf ("%d" , &w[i]); for (int i = 0 ; i < n; i++) scanf ("%lf" , &v[i]); double ans = binaryKnapsack (n, w, v, C); printf ("%. 1f\n" , ans); return 0 ; } }
最大上升子序列
问题分析
算法实现与分析